

For a few years now, every enterprise agent I built started the same way: from scratch. A new connector here, a handcrafted retrieval pipeline there, a fresh attempt to teach the agent what the business already knew. I built agent grounding the hard way more than once — custom RAG, bespoke chunking, my own identity plumbing — and watched two agents in the same tenant give two different answers to the same question because they had been grounded against two different copies of reality.
That is the production problem nobody puts on a slide. Context gets rebuilt per agent. Connectors sprawl. Answers drift. And the cost of all that plumbing lands on the same small group of engineers every time a new use case appears.
Microsoft IQ is Microsoft’s answer to that problem, and it reached general availability at Build 2026. This is the pillar post for the wider Microsoft IQ cluster on this blog: what each layer does, how they compose, and — just as important — where the GA reality differs from the keynote framing.
What Microsoft IQ actually is
Microsoft IQ is a shared, permission-aware intelligence layer that agents inherit, rather than rebuild. The pitch is simple: stop stitching connectors and pipelines into every agent, and ground them all against one governed view of how people work, how the business operates, and how to reuse knowledge.
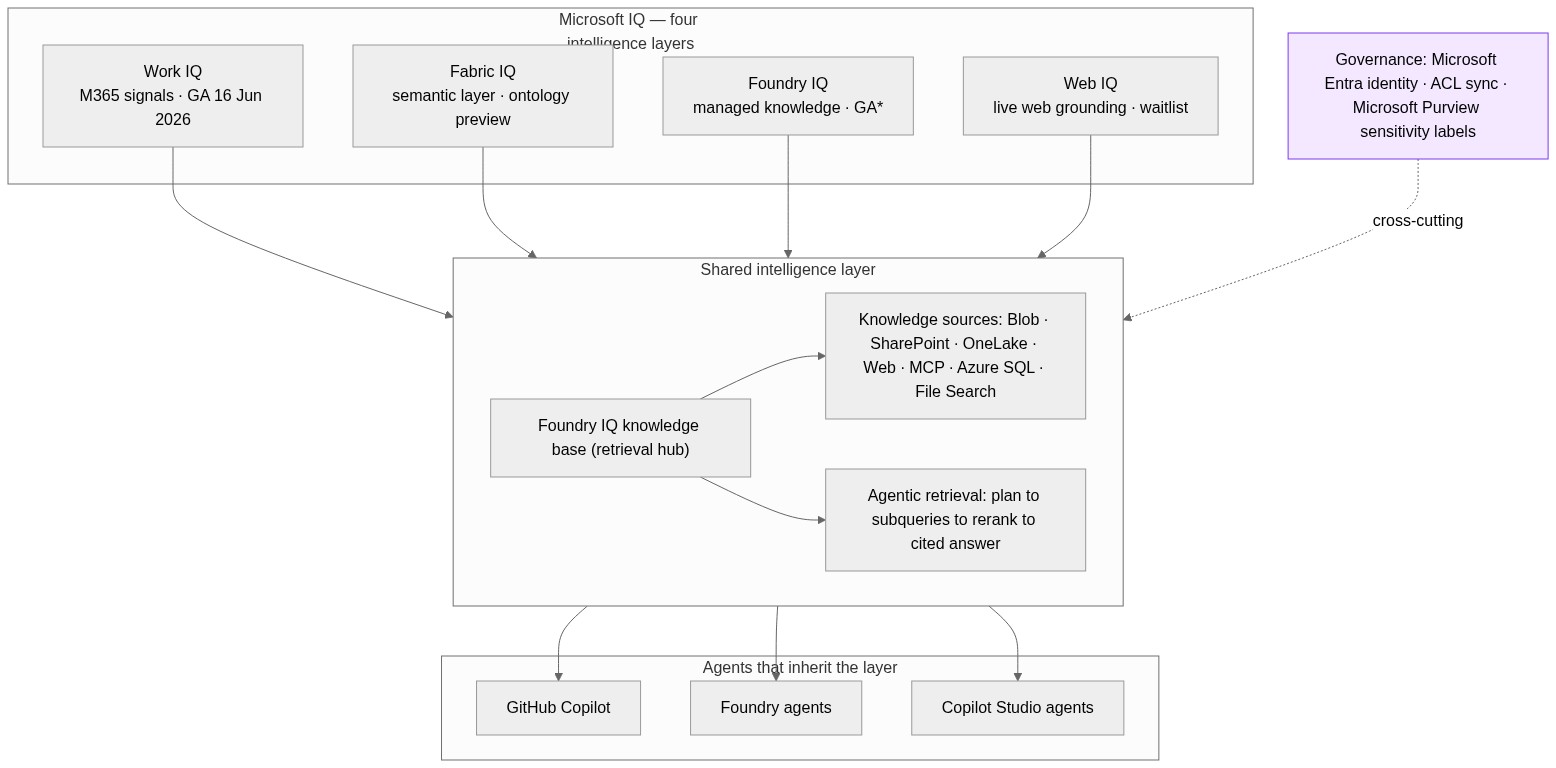
It is worth being precise about what it is not. Microsoft IQ is not a model, and it is not a chatbot feature. It sits underneath the agents you build in Copilot Studio, Microsoft Foundry, or GitHub Copilot, and feeds them context. It is composed of four layers — Work IQ, Fabric IQ, Foundry IQ, and Web IQ — and any agent across those three build surfaces can consume them.
The “GA” label, though, is an umbrella, not a uniform guarantee. Each of the four layers shipped at a different stage of maturity, and anyone scheduling a deployment this quarter — picking what to commit to in the next planning cycle — needs that breakdown up front, not buried in the small print. So I will give each layer its own section, with the state it actually shipped in.
Work IQ — the workplace context layer

Work IQ is the contextual intelligence layer for Microsoft 365. It captures the signals that describe how people actually work — emails, meetings, documents, Teams messages, people relationships, and collaboration patterns — and exposes them so an agent can reason over them in natural language.
The capability ships as a CLI and a Model Context Protocol server today, which is how AI assistants such as GitHub Copilot reach into a user’s M365 context. The broader public Work IQ APIs — REST, A2A, and MCP — are slated to reach GA on 16 June 2026.
The one thing an architect should know: as of writing, Microsoft Learn still labels Work IQ “public preview”, and accessing organisation data requires admin-consented permissions and tenant billing activation. Treat the GA date as imminent rather than banked, and plan the admin-consent step into your rollout — it is not a developer-self-serve switch.
Fabric IQ — the business-data semantic layer

Fabric IQ is the semantic layer over your business data. It elevates raw analytical, real-time, and operational data in OneLake into the language of the business — entities, relationships, rules, and actions — so that agents reason in terms of Customer, Shipment, or Breach rather than table columns.
It delivers this through two core items: semantic models and an ontology. And here is the GA nuance Microsoft’s umbrella headline glosses over — the Fabric IQ ontology is in preview. Learn marks it “ontology (preview)” consistently. The semantic-model side is more mature, and ontologies can be generated directly from Power BI semantic models already running in production, which is the realistic on-ramp for most estates that have years of Power BI behind them.
The one thing an architect should know: you can bootstrap a Fabric IQ ontology from an existing Power BI semantic model, keeping business terminology consistent across reports, agents, and apps — but treat the ontology itself as preview-grade until Microsoft says otherwise.
Foundry IQ — the managed knowledge layer

Foundry IQ is the layer that replaces the most plumbing, so it earns the most depth here. It turns fragmented enterprise content into governed, reusable knowledge that multiple agents can share.
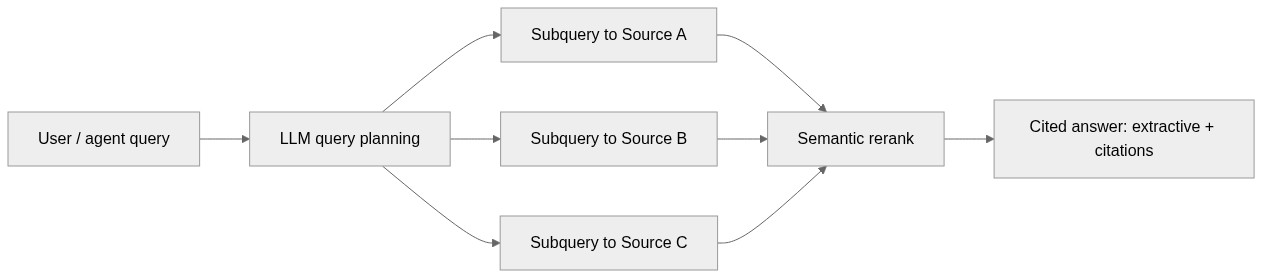
The model has three concepts worth learning precisely. A knowledge base is the top-level resource that orchestrates retrieval and carries a retrieval reasoning-effort setting of minimal, low, or medium. It is composed of knowledge sources — connections to indexed or remote content such as Azure Blob Storage, SharePoint, OneLake, the web, MCP, Azure SQL, and File Search. And it is queried through agentic retrieval: an LLM plans the query, decomposes a complex question into parallel subqueries across sources, semantically reranks the results, and returns extractive answers with citations the agent can trace.
Azure AI Search provides the underlying infrastructure. Crucially, a knowledge base is shareable: one knowledge base can ground many agents, and those agents can run in Foundry Agent Service, the Microsoft Agent Framework, or any custom app via the Azure AI Search knowledge base APIs. At Build 2026, Microsoft positioned Foundry IQ knowledge bases as the unifying point — bringing Work IQ, Fabric IQ, File Search, Azure SQL, and MCP behind a single, SLA-backed retrieval endpoint.
Now the candour. Foundry IQ’s GA is uneven, and Microsoft says so on the concept page itself: some features are generally available while others remain in preview, and which is which depends on the Search Service REST API version you call. The same page notes that the Foundry portal and Azure portal still expose all agentic retrieval features as preview-only. So “Foundry IQ is GA” is true and incomplete at the same time — the answer depends on how you call it.
The one thing an architect should know: before you plan a production rollout, pin down which Search Service REST API version your code targets, because that single choice determines whether you are on a GA or a preview surface.
Web IQ — the live web-grounding layer

Web IQ is the newest layer, announced at Build 2026. It is web grounding rebuilt for LLMs and multi-step agents: a suite of AI-native APIs returning ranked, citation-ready context across web pages, news, images, and video, built on two decades of Bing infrastructure rather than SERP scraping.
The engineering numbers are the headline. Microsoft claims roughly 164ms P95 latency — close to 2.5x faster than the best alternative — with fewer tokens per query. It is model-agnostic and MCP-native over JSON-RPC 2.0, so there is no inference lock-in, and it is benchmarked against suites including DeepSearchQA.
The one thing an architect should know: Web IQ is limited access and waitlist-only today, prioritised for enterprise customers working with Microsoft account teams. If live web grounding matters to your roadmap, the action this month is to join the waitlist, not to design around guaranteed availability.
How the layers compose
The architecture is cleaner than the four-product naming suggests. The four IQ layers feed a shared intelligence layer that any agent — GitHub Copilot, a Foundry agent, or a Copilot Studio agent — consumes. Foundry IQ knowledge bases act as the retrieval hub that the others can flow through. Cutting across all of it is governance: queries run under the caller’s Microsoft Entra identity, ACLs synchronise for supported sources, and Microsoft Purview sensitivity labels are enforced end to end.
The retrieval path inside Foundry IQ is the part most worth internalising, because it is where the “no complex RAG” claim meets reality: a query is planned by an LLM, decomposed into parallel subqueries across sources, semantically reranked, and returned as a cited answer.
Where this falls short today
“No complex RAG” is a marketing claim, not an engineering fact. Foundry IQ genuinely removes connector and pipeline plumbing, and that is real value. It does not remove the need to understand chunking behaviour, to evaluate retrieval quality, or to model cost. You are not maintaining the pipeline; you are still responsible for whether it returns the right thing at a price you can defend.
The GA label is uneven. Microsoft IQ is GA as an umbrella, but Fabric IQ’s ontology is preview, Web IQ is waitlist-only, and Foundry IQ’s GA depends on which Search REST API version you call. If you are signing off a production plan, build that table honestly: per layer, what is GA, what is preview, what is gated.
Microsoft has promised programmable enterprise context before. Microsoft Graph was supposed to be this a decade ago. Semantic Kernel memory abstractions and earlier Copilot extensibility models each hit walls — latency, schema drift, identity resolution. What is different this time is a retrieval-planning layer doing the grounding and GA APIs rather than perpetual preview. That difference is meaningful. It is also unproven at production scale, and I would hold both thoughts at once.
Lock-in is the trade. An intelligence layer this deep couples your agent estate to the Microsoft stack. For organisations already on M365, Fabric, and Dynamics, that is leverage of investment you have already made. For hybrid estates, it is a strategic decision to make deliberately, not a default to drift into.
Pricing and billing clarity is thin at GA. Work IQ requires tenant billing activation, and the consumption models across the layers are not yet fully documented. Before you commit a budget, get your Microsoft account team to put the per-layer billing model in writing — that is the gap most likely to surprise you later.
What I would do this month
Concrete, role-aware next steps if you own enterprise agent architecture:
- Pin the Search Service REST API version your Foundry IQ code targets, and confirm whether that puts you on a GA or a preview surface before anything reaches production.
- Plan for the Work IQ API GA on 16 June 2026 — including the admin-consent and tenant-billing steps — rather than assuming developer self-serve.
- Bootstrap a Fabric IQ ontology from an existing Power BI semantic model in a sandbox, so you learn the preview behaviour without betting a production workload on it.
- Join the Web IQ waitlist now if live web grounding is on your roadmap, because availability is gated and lead time is unknown.
- Ask your account team for the per-layer consumption and billing model in writing before you size a budget.
Where this cluster goes next
This pillar is deliberately broad. Each layer deserves its own engineering deep-dive, and those are coming — starting with Foundry IQ versus a do-it-yourself RAG pipeline, the comparison I get asked about most. Fabric IQ ontologies, the Work IQ API surface, and Web IQ’s grounding economics will each get their own treatment. When those land, this post will link out to them from the sections above.
The short version: Microsoft IQ is the first time the “shared enterprise context” promise has arrived with a retrieval-planning layer and real GA APIs behind it. That is worth taking seriously. It is also worth reading the GA label one layer at a time.
References
- Microsoft IQ — product overview
- What is Foundry IQ? — Microsoft Learn
- Microsoft Web IQ
- What is Fabric IQ? — Microsoft Learn
- Work IQ overview — Microsoft Learn
- Microsoft Build 2026 — announcement hub
Image credits
The layer diagrams in this post are reused from the Microsoft IQ product page with attribution to Microsoft:
- Banner and the four layer illustrations (Work IQ, Fabric IQ, Foundry IQ, Web IQ): Microsoft IQ
The two architecture diagrams are my own. All other commentary, code, and opinions in this post are my own and reflect lessons from building enterprise agent grounding the hard way.

Leave a comment